ICLR 2023 is just around the corner! The quality of the technical program relies critically on the dedicated and professional service from volunteers in the ICLR community to serve as reviewers. We would like to thank the 5K+ reviewers who have helped shape this year’s technical program. In particular, we would like to recognize notable reviewers and area chairs who have contributed significantly. Their names and pictures are posted on the ICLR 2023 website.
Selection Process of Notable Reviewers and Area Chairs Professionalism, technical expertise, and ability to write good reviews were the main selection criteria used. The following factors (not exhaustive list) were considered during the selection process.
Professionalism:
High sense of responsibility
Responsive to requests, questions
Completes tasks in timely manner or early
Proactive in taking initiatives and asking questions to preempt undesirable consequences
Resourcefulness, e.g. ability to get last minute reviews, crash reviewers or replacement Area Chairs
Diligence in reviewer duty, engages with authors
Technical Expertise and Ability to Write Good Reviews or Meta Reviews:
Reviews are insightful, thorough, comprehensive, respectful, or convincing
Reads up on related literature and references
Adept in making critical assessments when there is new sources of information, differences in opinion
Displays tact and diplomacy in one’s communication and reviews to preempt unnecessary misunderstanding or make feedback more likely be accepted
Compares with related prior work critically and comprehensively
Gives constructive feedback that helps the authors improve the quality of the paper
Both qualitative and quantitative metrics were used to filter and rank the reviewer candidates. Performance consistency across reviewed papers were also taken into account.
Notable Area Chairs
A. Rupam Mahmood Aditya Krishna Menon Agata Lapedriza Diederik Kingma Hinrich Schuetze Hongfu Liu Hung-yi Lee Jakob Foerster Jan Buys Katja Hofmann Kevin Small Lei Li Marlos Machado Matt Kusner Matthias Seeger Michel Galley Miltiadis Allamanis Min Wu Piotr Koniusz Shafiq Joty Shang-Wen Li Tongliang Liu Vittorio Murino Wei Lu Yale Song Yu-Xiong Wang
Notable Reviewers
Vinu Sankar Sadasivan Chuanhao Li Adrián Javaloy Albert Zeyer Alon Brutzkus Arnab Ghosh Cagatay Yildiz David Krueger Davide Bacciu Davis Rempe Dennis Soemers Dhruva Tirumala Dmitry Kangin Ehsan Hajiramezanali Eleni Triantafillou Ethan Fetaya Fanghui Liu Ferdinando Fioretto Gang Chen Gaurang Sriramanan George Trimponias Gido M van de Ven Glen Berseth Gregory Slabaugh Hong Liu Hongning Wang Jack Valmadre Jean-Francois Ton Jennifer Hobbs Jonathan Schwarz Karsten Kreis Kevin J Liang Kyle Hsu Linwei Wang Mathias Lechner Mathurin MASSIAS Mikael Henaff Nicholas Monath Nikunj Saunshi Peng Hu Philip Ball Pietro Michiardi Raphaël Dang-Nhu Rohan Taori Sercan O Arik Sergio Valcarcel Macua Shuai Li Stephen Tian Tianyi Chen Weinan Song Xiaoxiao Li Xinlei Chen Xinyun Chen Ya-Ping Hsieh Yann Dubois Yaxuan Zhu Yi Wu Yi-Hsuan Tsai Yu Yao Yuming Jiang Yunbo Wang Zaiwei Chen
For ICLR 2022, we introduced a mentoring scheme for reviewers, who are new to reviewing for machine learning conferences. Below, we describe the motivation, the implementation, and the result.
Motivation
Finding reviewers for conferences or journals is challenging: The reviewing system is almost a closed circle with unclear/undefined processes to join, and where members of that circle are frequently overburdened with review requests. For example, at ICLR 2022 we merged reviewer databases from NeurIPS 2021, ICML 2021, and ICLR 2021 to reach out to more than 11,000 reviewers. We believe this kind of approach is fairly common to reach some critical mass in terms of reviewers. However, this also means that reviewers in those databases are contacted over and over again. On the other hand, as the machine learning community is growing, there’s no clear path for new reviewers to join. Sometimes potential reviewers reach out to the program chairs and ask whether they can join or where supervisors (who are already in the pool) add their PhD students to the pool. These approaches do not scale, and we miss out on many potential reviewers who could do a great job, but who cannot enter the reviewer pool through the ‘usual means’.
This year, we had an open call for reviewer self-nominations, and we received approximately 700 requests from people, who did not get an invitation to review. About 250 of these applications were requests from reviewers with great experience in reviewing for machine learning conferences, and who should have been included in the original invites, but who fell through the cracks for some reason. However, there were also more than 350 requests from people who have either never (or very little) reviewed for major machine learning conferences. For these ‘new reviewers’, we decided to establish a mentoring program, where they are matched with an experienced and empathetic mentor, who supports them with the writing of a review.
Implementation
We hand-picked 30 mentors (who were neither reviewers nor area chairs at ICLR) to support approximately 300 new reviewers. Based on their domain expertise, new reviewers will be assigned a single paper submitted to ICLR 2022 for which they drafted a review within 10 days. We provided the new reviewers with examples of good and bad reviews, a checklist and a template to simplify the creation of the review.
When the review was done, they reached out to their assigned mentor, who provided feedback on the quality of the review. For example, they checked whether feedback is constructive and helpful or whether the language is polite. The mentors were not expected to have read the paper, but only to provide feedback on the reviews themselves. Mentors and new reviewers had about 10 days to iterate after which the mentor made a decision whether the review was of sufficiently high quality (at this point the mentorship program ended). If that was the case, the review (and the reviewer) entered the regular pool of reviewers for ICLR, which allowed them to participate in discussions. 220 ‘new’ reviewers entered the reviewer pool in this way; the timing was synced with the submission of the regular reviews.
Reviewer Mentors
We want to express our gratitude to the reviewer mentors: Arno Solin, Sergey Levine, Martha White, Hugo Larochelle, James R. Wright, Amy Zhang, Sinead Williamson, Nicholas J. Foti, Samy Bengio, Nicolas Le Roux, Matthew Kyle Schlegel, Hugh Salimbeni, Andrew Patterson, Andrew Jacobsen, Mohammad Emtiyaz Khan, Ulrich Paquet, Carl Henrik Ek, Iain Murray, Cheng Soon Ong, Markus Kaiser, Savannah Jennifer Thais, Finale Doshi-Velez, Irina Higgins, Mark van der Wilk, Edward Grefenstette, Brian Kingsbury, Pontus Saito Stenetorp, David Pfau, Danielle Belgrave, Mikkel N. Schmidt.
Statistics
‘Regular’ reviewer
Mentee
Average review length
501 words
859 words
Average number of discussion comments
1.54
1.73
Average comment length
128 words
165 words
Table 1: Performance of ‘regular’ reviewers and reviewer mentees measured in terms of review length and interactions during the rebuttal period.
We looked at some basic statistics to see how reviewer mentees compare with ‘regular’ reviewers (see table above). It turns out that reviews by reviewer mentees were longer on average, compared with reviews that came through the regular reviewer pool. Furthermore, on average, mentees also showed more engagement in the discussion (see average number of comments and average length of comments). While the discussion period was outside the mentorship program, i.e., no further feedback from the mentors was provided, we assume that the increased level of engagement is related to a lower paper load (1 paper for mentees, 1.87 papers on average across all reviewers) and the fact that reviewer mentees were fairly comfortable with the paper they reviewed.
Survey Feedback
A survey conducted in early February 2022 (i.e. after the decision notifications) amongst all reviewer mentees revealed (130 respondents):
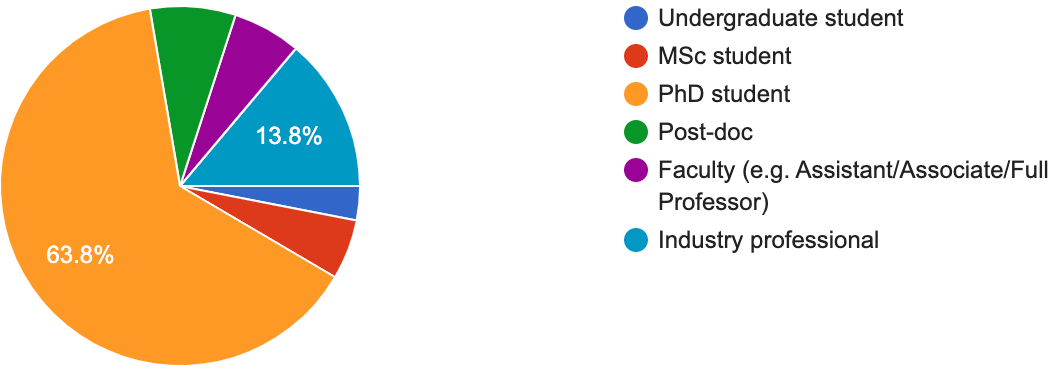
Mentees were predominantly PhD students (65%); see Figure above
Most mentees had reviewed never (53%) or once (26%) for a major machine learning conferences
Goals (>95% (strongly) agree) and the process (>91% (strongly) agree) of the mentorship program were clear
Reviewer guidelines were useful (>93% (strongly) agree)
Paper assignments based on affinity scores were good (>85% (strongly) agree), although 4% of the respondents found the assigned papers too far from their research expertise.
Mentees had enough time to review the paper (>93% (strongly) agree)
Mentor was responsive and provided useful feedback (90% (strongly) agree)
77% of the respondents were promoted to ‘regular’ reviewer by their corresponding mentors
Mentees found the mentorship program useful (>93% (strongly) agree)
Mentees recommend that the mentorship program should be offered again (>96% (strongly) agree)
The success of the mentorship program very much relies on the mentors and their timely feedback. If communication between mentor and mentee is stuck, the learning experience is somewhat reduced, which a few people pointed out. However, the vast majority of respondents highly valued the discussions and communication with mentors, which helped them to write a good review.
Summary
In 2022, we piloted a mentorship program for reviewers with little experience reviewing for machine learning conferences. To support these new reviewers, we assigned them an experienced reviewer to support them in writing a high-quality review. Most of the reviews were of very high quality, so that they entered the regular reviewing pool/cycle. Overall, the mentorship program received overwhelmingly positive feedback.