We thank everyone who prepared and submitted a workshop proposal to ICLR 2026. We were impressed by the quality of the proposals. This year, we received an unprecedented number of 135 valid submissions and were able to accept 40 proposals based on the number of available rooms in the conference venue. We particularly want to thank our team of reviewers.
Selection Process
Working within the workshop space allocation in Rio de Janeiro, the workshop chairsworked to balance multiple goals. Workshop organizers were provided with guidance criteria for proposals, including hard workshop requirements including COI management, participation limits, platforming contributed work, Tiny Paper track support, in-person planning, and LLM usage policy. Reviewers were asked to check these criteria. Each proposal received at least three reviews. All reviews and scores were checked by workshop chairs for fairness and errors. The high-ranking proposals were further evaluated on the softer selection criteria. In particular, workshop chairs aimed to ensure diversity – same topics, speakers, and organizers are not heavily recurring across multiple workshops. Final decisions and reviews were then released to authors. More details will be presented at the conference town hall.
All organizers are recommended to follow the honor code and do not add new organizers(proposal authors) or change titles after submission. We recommend workshops to follow the same LLM Usage Policies for ICLR 2026 main conference.
The topics of ICLR 2026 workshops range over Agentic Systems, Alignments, Continual Learning, Generative Models, Memory, Reasoning, Applications, etc. – a diverse set of representation learning advances.
ICLR 2026 Workshops in Numbers
151: workshop proposal submissions (vs 122 in 2025, 1.24x increase)
417: reviews submitted by 74 workshop proposal reviewers
Awards Committee: Cordelia Schmid, Guy Van der Broek, Jun Zhu, Katerina Fragkiadaki, Lihong Li, Luke Zettlemoyer, Natasha Jaques, Tao Yu, Yarin Gal
Selection Process
The ICLR 2025 Outstanding Paper Committee went through a two-stage selection process to identify a collection of outstanding papers and honorable mentions that showcase excellent research presented at this conference. The committee began with an initial pool of 36 papers, which were either recommended by the area chairs or received exceptional scores from reviewers. Committee members first conducted preliminary reviews to select finalists. The finalists were read by all members of the committee who ranked the papers based on factors such as theoretical insights, practical impacts, exceptional writing, and experimental rigor. The program chairs confirmed the decisions.
In total there are 3 Outstanding Paper winners, and 3 Honorable Mentions. Congratulations to all the authors for their exceptional contributions to ICLR!
SAM 2: Segment Anything in Images and Videos. Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollar, Christoph Feichtenhofer
(This post is written by James Zou, Associate Program Chair for ICLR 2025, and Nitya Thakkar)
Peer review is a key element of research and innovation. However, it faces growing strain from the rapidly rising volume of paper submissions, particularly at AI conferences; as a result, authors increasingly express dissatisfaction with low-quality reviews. Therefore, there is growing interest in exploring how large language models (LLMs) can enhance the quality and usefulness of peer reviews for authors.
At ICLR 2025, we piloted an AI agent that leveraged multiple LLMs to provide reviewers with optional feedback on their reviews. This feedback agent was optimized to give suggestions that made reviews more informative, clear, and actionable. We also implemented multiple LLM-based guardrails, called reliability tests, which evaluated specific attributes of the AI feedback before it was posted. The agent provided feedback to 18,946 randomly selected reviews (see Figure 1A). During the review period, reviewers could choose to ignore the LLM feedback (Not updated) or revise their review in response (Updated), as the system did not make any direct changes. See our previous blog post, Assisting ICLR 2025 reviewers with feedback, for more details about the IRB-approved study setup.
Key Findings
Figure 1: (A) Among all ICLR 2025 reviews, 22,467 were randomly selected to receive feedback (feedback group), and 22,364 were randomly selected not to receive feedback (control group). Among those who received feedback, 26.6% of reviewers updated their reviews. In total, reviewers who updated incorporated 12,222 feedback items. (B) (Top) Most reviews were submitted 2-3 days before the ICLR review deadline (November 4, 2024). (Bottom) Reviewers who received feedback were much more likely to update their reviews than those in the control group. Across both groups, reviewers were more likely to update their review if they submitted it early relative to the deadline.
Our findings reveal several significant impacts of this LLM-based system:
Reviewers incorporated 12,222 specific suggestions from the feedback agent into their reviews, indicating that many reviewers found the LLM recommendations helpful. In total, 26.6% of reviewers who received feedback updated their reviews (Figure 1A).
In a blinded preference assessment, machine learning researchers found that LLM feedback improved review quality in 89% of the cases.
Reviewers who updated their reviews after receiving LLM feedback increased review length by an average of 80 words, suggesting more detailed reviews.
LLM feedback led to more engaged discussions during the rebuttal period, evidenced by longer author rebuttals and reviewer responses (see Table 1). This could be due to clearer and more actionable reviews resulting from the feedback, leading to more productive rebuttals.
There was no statistically significant difference in the acceptance outcomes of the final papers between the feedback and control groups. This is consistent with the feedback agent’s goal of enhancing the author-reviewer discussion rather than advocating for or criticizing the paper.
Table 1: Average rebuttal and reply lengths across control and feedback groups, and between reviewers who did or did not update their review after receiving feedback. We observe that being selected to receive feedback causally increased the length of author rebuttals by an average of 48 words (*** p ≤ 0.001) for reviews written by reviewers selected to receive feedback. We also see that the average length of reviewer replies to author rebuttals is longer among those in the feedback group (***p ≤ 0.001). Note that the feedback group includes reviews that were selected to receive feedback but ignored the feedback, which can dilute the effect size.
Our large randomized control study highlights the potential of a carefully designed LLM-based system to enhance peer review quality at scale. By providing targeted feedback to reviewers at ICLR 2025 and enabling them to choose how to incorporate it, we observed improvements in review specificity, engagement, and actionability. We provide a more detailed analysis and discussions of the limitations of LLM feedback in our paper. As LLM capabilities continue to advance, more research and rigorous assessments are needed to understand how AI can responsibly enhance peer review.
Nitya Thakkar, Mert Yuksekgonul, Jake Silberg, James Zou (Associate Program Chair) The Review Feedback Agent Team
Carl Vondrick, Rose Yu, Violet Peng, Fei Sha, Animesh Garg ICLR 2025 Program Chairs
We are honored to announce the Test of Time awards for ICLR 2025. This award recognizes papers published ten years ago at ICLR 2015 that have had a lasting impact on the field. The 2025 program chairs and general chair reviewed the papers published at ICLR 2015, and selected the two papers below for their profound influence and impact on machine learning today.
Congratulations to the authors of the Test of Time winner and runner up!
As one of the most widely adopted optimization algorithms in deep learning, Adam revolutionized neural network training, enabling significantly faster convergence and more stable training across a wide variety of architectures and tasks. The algorithm automatically adjusts parameter-specific learning rates based on first and second moments of gradients, handling sparse gradients and non-stationary objectives. Adam’s practical success has made it the default optimizer for countless state-of-the-art models, from computer vision and natural language processing to reinforcement learning, demonstrating remarkable versatility across problem domains and neural network architectures.
Runner Up
Neural Machine Translation by Jointly Learning to Align and Translate Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio https://arxiv.org/abs/1409.0473
Introducing a form of attention, this paper fundamentally changed how sequence-to-sequence models process information. Before this work, encoder-decoder architectures usually compressed entire input sequences into fixed-length vectors, creating memory bottlenecks for longer sequences. The proposed approach enabled the model to “attend” to different parts of the source sentence dynamically during translation, allowing for processing of relevant contextual information. This attention mechanism has since become a cornerstone of modern deep learning, extending far beyond machine translation to form the foundation for transformers and large language models. The paper’s practical impact has been immense, making it one of the most influential contributions to neural network architectures.
We are pleased to announce the keynote speakers for ICLR 2025. These speakers were selected to cover a range of topics, both within core machine learning as well as application areas. Those attending ICLR can see the full schedule online.
The invited speakers in alphabetical order are (titles and abstracts are subject to change):
Danqi Chen (Princeton University)
Title: Training Language Models in Academia: Challenge or Calling?
Abstract: Training large language models has become a defining pursuit in modern machine learning—one that is almost entirely led by industry, fueled by massive computational resources and guided by scaling laws that reward ever-larger models and datasets. For academic researchers, participating in this space can feel out of reach. The barriers—limited compute, infrastructure, and access to proprietary data—are real and growing. Still, I believe academia has an essential role to play. Even with constraints, there are important scientific questions and meaningful opportunities that academic research is uniquely positioned to tackle. By engaging with the training process itself, we can deepen our understanding of language models and develop novel and efficient approaches that complement large-scale efforts. In this talk, I’ll share my lab’s research efforts over the past two years in both pre-training and post-training of language models under an academic budget. Our work has aimed to better understand training dynamics, innovate within limitations, and release artifacts that benefit the broader research community. I’ll also highlight three areas where academic researchers can make significant contributions: (1) developing small but capable models, (2) understanding and improving training data, and (3) advancing post-training methods on top of open-weight models. My hope is to encourage broader engagement with LM training in academia, and to foster new forms of collaboration between academic and industry research.
Bio: Danqi Chen is an Associate Professor of Computer Science at Princeton University and co-leads the Princeton NLP Group. She also serves as an Associate Director of Princeton Language and Intelligence (PLI), an initiative focused on developing fundamental research of large AI models. Her recent research centers on training, adapting, and understanding language models (LMs), with an emphasis on making them more accessible to academia. Before joining Princeton, Danqi was a visiting scientist at Facebook AI Research in Seattle. She earned her Ph.D. from Stanford University (2018) and her B.E. from Tsinghua University (2012), both in Computer Science. Her work has been recognized with a Sloan Fellowship, an NSF CAREER Award, a Samsung AI Researcher of the Year Award, and multiple outstanding paper awards from ACL and EMNLP.
Dawn Song (University of California, Berkeley)
Title: Towards Building Safe and Secure AI: Lessons and Open Challenges
Abstract: Recent advancements in AI and LLM agents have unlocked powerful new capabilities across a wide range of applications. However, these advancements also bring significant risks that must be addressed. In this talk, I will explore the various risks associated with building and deploying AI and LLM agents and discuss approaches to mitigate them. I will also examine how frontier AI and LLM agents could be misused, particularly in cyber security attacks, and how they may reshape the cyber security landscape. Ensuring a safe AI future demands a sociotechnical approach. I will outline our recent proposal for a science- and evidence-based AI policy, highlighting key priorities to deepen our understanding of AI risks, develop effective mitigation approaches, and guide the development of robust AI policies.
Bio: Dawn Song is a Professor in Computer Science at UC Berkeley and Co-Director of Berkeley Center for Responsible Decentralized Intelligence. Her research interest lies in AI and deep learning, security and privacy, and decentralization technology. She is the recipient of various awards including the MacArthur Fellowship, the Guggenheim Fellowship, the NSF CAREER Award, the Alfred P. Sloan Research Fellowship, the MIT Technology Review TR-35 Award, ACM SIGSAC Outstanding Innovation Award, and more than 10 Test-of-Time Awards and Best Paper Awards from top conferences in Computer Security and Deep Learning. She has been recognized as Most Influential Scholar (AMiner Award), for being the most cited scholar in computer security. She is an ACM Fellow and an IEEE Fellow. She obtained her Ph.D. degree from UC Berkeley. She is also a serial entrepreneur and has been named on the Female Founder 100 List by Inc. and Wired25 List of Innovators.
Song-Chun Zhu (Peking University and Tsinghua University)
Title: AGI: Framework, Prototype, Definition and Benchmark
Abstract: In this talk, I will present a set of work done at the Beijing Institute of General Artificial Intelligence (BIGAI) and Peking University on AGI, which is also called TongAI as the Chinese character ‘Tong’ means ‘general’ and contains the letters ‘A’, ‘G’ and ‘I’. I will start with introducing a digital agent — a little girl who lives and learns continuously in simulated diverse physics-realistic environments with multi-physics and social interactions. The little girl with a nickname ‘TongTong’ is driven by her own value system with desires and goals which generates plans and actions. Then I will reveal the framework underneath this self-conscious agent with three interconnected components: Cognitive architecture (C), the potential functions (U) representing skills, and the value functions (V). Then we define various AGI systems as points in this joint (C,U,V) –space. This framework represents a paradigm shift from the popular “data-driven” “large data for small tasks” statistical paradigm which we pioneered at Harvard, Brown and UCLA since the early 1990s, to the “value-driven” “small data for large tasks” paradigm which I have been advocating since 2010. Then I will introduce TongTest as new criteria, benchmarks and test platform for measuring the general intelligence of various AI agents on performing multi-modal embodied tasks in complex environments. The TongTest has gone way beyond the Turing test in complexity and integrates results from developmental psychology and anthropology. It assesses the intelligence of TongTong to match a 3-4 years old child. In the talk, I will also show some recent work on humanoid robotics and applications, and discuss the Eastern philosophical thinking what makes humans and intelligence, and how morality and social norm emerge from the CUV framework as a solution to AGI safety.
Bio: Song-Chun Zhu is currently director of Beijing Institute for General Artificial Intelligence (BIGAI) – a non-profit research organization, and Chair Professor at Peking University and Tsinghua University jointly. He is also dean of both School of Intelligence Science and Technology and Institute for Artificial Intelligence at Peking University. He received Ph.D. degree in computer science from Harvard University in 1996, and after that he worked at Brown, Stanford and UCLA where he established an inter-disciplinary center of Vision, Cognition, Learning and Autonomy (VCLA@UCLA 2002-2020) before he returned to China in late 2020. He has published 400+ articles in AI areas including CV, Cognition, Robotics, ML, NLP, MAS et al. His scientific contributions have garnered various recognitions, including the Marr Prize (2003), twice Marr prize honorary nominations (1999,2007), Sloan Fellowship (2001), J.K. Aggarwal Prize (2008), Helmholtz Test-of-Time Award (2013) , computational modeling prize at CogSci (2017) etc. He established the Lotus Hill Institute in 2005 to launch large-scale image annotation and pioneered data-driven statistical approaches. He served as general chair for CVPR 2012 and 2019., and led twice the Multi-University Research Initiatives (MURI 2010-2015, 2015-2020) on scene understanding, visual commonsense reasoning and robot autonomy in the US. His research has been pursuing a general unified theory of intelligence.
Tim Rocktäschel (Google DeepMind and University College London)
Title: Open-Endedness, World Models, and the Automation of Innovation
Abstract: The pursuit of Artificial Superintelligence (ASI) requires a shift from narrow objective optimization towards embracing Open-Endedness—a research paradigm, pioneered in AI by Stanley, Lehman and Clune, that is focused on systems that generate endless sequences of novel but learnable artifacts. In this talk, I will present our work on large-scale foundation world models that can generate a wide variety of diverse environments that can in turn be used to train more general and robust agents. Furthermore, I will argue that the connection between Open-Endedness and Foundation Models points towards automating innovation itself. This convergence is already yielding practical results, enabling self-referential self-improvement loops for automated prompt engineering, automated red-teaming, and AI debate in Large Language Models, and it hints at a future where AI drives its own discoveries.
Bio: Tim Rocktäschel is the Director, Principal Scientist, and the Open-Endedness Team Lead at Google DeepMind. He is also a Professor of Artificial Intelligence at the Centre for Artificial Intelligence in the Department of Computer Science at University College London (UCL), where he is the Principal Investigator of the UCL Deciding, Acting, and Reasoning with Knowledge (DARK) Lab. He is also a Fellow of the European Laboratory for Learning and Intelligent Systems (ELLIS). Previously, he served as a Manager, Research Scientist, and Area Lead at Meta AI (FAIR), a Postdoctoral Researcher in Reinforcement Learning at the Whiteson Research Lab at the University of Oxford, a Junior Research Fellow in Computer Science at Jesus College, and a Stipendiary Lecturer in Computer Science at Hertford College. He obtained his Ph.D. from UCL under the supervision of Sebastian Riedel, receiving a Microsoft Research Ph.D. Scholarship in 2013 and a Google Ph.D. Fellowship in 2017. His work focuses on Artificial General Intelligence, Open-Endedness, and Self-Improvement, and has received Best Paper Awards at ICML.
Yi Ma (Hong Kong University)
Title: Pursuing the Nature of Intelligence
Abstract: In this talk, we will try to clarify different levels and mechanisms of intelligence from historical, scientific, mathematical, and computational perspective. From the evolution of intelligence in nature, from phylogenetic, to ontogenetic, to societal, and to artificial intelligence, we will try to shed light on how to understand the true nature of the seemingly dramatic advancements in the technologies of machine intelligence in the past decade. We achieve this goal by developing a principled mathematical framework to explain the practice of deep learning from the perspective of compressive data encoding and decoding. This framework not only reveals true nature hence limitations of the current practice and but also provides principled guidelines to develop more complete and more efficient learning architectures and systems. Eventually, we will clarify the difference and relationship between Knowledge and Intelligence, which may guide us to pursue the goal of developing systems with true intelligence.
Bio: Yi Ma is a Chair Professor in Artificial Intelligence, the inaugural director of the School of Computing and Data Science and the Institute of Data Science of the University of Hong Kong since 2023. His research interests include computer vision, high-dimensional data analysis, and integrated intelligent systems. Yi received his two bachelor’s degrees in Automation and Applied Mathematics from Tsinghua University in 1995, two master’s degrees in EECS and Mathematics in 1997, and a PhD degree in EECS from UC Berkeley in 2000. He served on the faculty of UIUC ECE from 2000 to 2011, the principal researcher and manager of the Visual Computing group of Microsoft Research Asia from 2009 to 2014, and the Executive Dean of the School of Information Science and Technology of ShanghaiTech University from 2014 to 2017. He was on the faculty of UC Berkeley EECS Department from 2018-2023, where he continues to be a visiting professor. He has published over 65 journal papers, 150 conference papers, and three textbooks on 3D vision, generalized PCA, and high-dimensional data analysis. He received the NSF Career award in 2004 and the ONR Young Investigator award in 2005. He also received the David Marr prize in computer vision from ICCV 1999 and best paper awards from ECCV 2004 and ACCV 2009. He has served as the Program Chair for ICCV 2013 and the General Chair for ICCV 2015. He is a Fellow of IEEE, ACM, and SIAM.
Zico Kolter (Carnegie Mellon University)
Title: Building Safe and Robust AI Systems
Abstract: As AI systems become more powerful, it is increasingly important that developers be able to strictly enforce desired policies for the systems. Unfortunately, via techniques such as adversarial attacks, it has traditionally been possible to circumvent model policies, allowing bad actors to manipulate LLMs for unintended and potentially harmful purposes. In this talk, I will highlight several recent directions of work that are making progress in addressing these challenges, including methods for robustness to jailbreaks, safety pre-training, and methods for preventing undesirable model distillation. I will additionally highlight some of the areas I believe to be most crucial for future work in the field.
Bio: Zico Kolter is a Professor and Department Head of the Machine Learning Department at Carnegie Mellon University. Additionally, he serves on the Board of Directors at OpenAI, where he chairs the safety and security committee, is a co-founder and the Chief Technical Advisor of Gray Swan AI, an AI Security company, and is a Chief Expert at Robert Bosch, LLC. His work spans several topics in machine learning, including work in AI safety and robustness, LLM security, the impact of data on models, implicit models, and more. He is a recipient of the DARPA Young Faculty Award, a Sloan Fellowship, and best paper awards at NeurIPS, ICML (honorable mention), AISTATS (test of time), IJCAI, KDD, and PESGM.
(This post is written by James Zou, Associate Program Chair)
Obtaining constructive and high-quality peer reviews at AI conferences has become increasingly challenging due to the rapidly rising volume of paper submissions. For example, ICLR experienced year-over-year submission increases of 47% in 2024 and 61% in 2025. As submission numbers grow, the demand on reviewers increases, often leading to inconsistent review quality. To help, for ICLR 2025 we are introducing a review feedback agent that identifies potential issues in reviews and provides feedback to reviewers for improvements.
The goal of this system is to help make reviews more constructive and actionable for authors. The review feedback agent will provide suggestions on three potential categories of issues in reviews. We curated these categories by compiling public comments and evaluating reviews from previous ICLRs to identify common issues.
The feedback areas are:
Encouraging reviewers to rephrase vague review comments, making them more actionable for the authors.
Highlighting sections of the paper that may already address some of the reviewer’s questions.
Identifying and addressing unprofessional or inappropriate remarks in the review.
We provide an example of a comment that would be flagged by our system for each category and an example feedback below.
The feedback system will not replace any human reviewers. The agent will not write reviews or make automated edits to reviews. Rather, it will serve as an assistant, providing optional feedback that reviewers can choose to incorporate or disregard. Every ICLR submission will be assessed solely by human reviewers, and the final acceptance decisions will be made by ACs, SACs, and reviewers, as in previous ICLR conferences.
The feedback will be provided for a randomly selected subset of initial reviews to enable comparisons and assess its impact. Reviewers will have an opportunity to update their review, should they wish, before the reviews are available to the authors. Feedback will be sent to the reviewer within a few hours of submitting a review. There will be no feedback on subsequent reviewer responses, and no further interaction between the reviewer and the feedback system. Moreover, the feedback will only be visible to the reviewer and the ICLR program chairs; it will not be shared with other reviewers, authors, or ACs and will not be a factor in the acceptance decisions. We have designed the feedback system using a pipeline of multiple LLMs to minimize hallucinations and enhance the quality of the feedback. The system has been carefully tested on publicly available ICLR 2024 reviews.
After the final paper decisions have been released, we will distribute an anonymous, voluntary survey to authors, reviewers, and ACs to gather feedback. We will carefully analyze the responses to assess the pilot system’s impact and to guide improvements for future iterations.
Nitya Thakkar, Mert Yuksekgonul, Jake Silberg, James Zou (Associate Program Chair) The Review Feedback Agent Team
Carl Vondrick, Rose Yu, Violet Peng, Fei Sha, Animesh Garg ICLR 2025 Program Chairs
Last year, the International Conference on Learning Representations (ICLR) hosted a select subset of papers published at the Transactions on Machine Learning Research (TMLR) as ICLR poster presentations. We have received positive feedback on this pilot program from both participants at ICLR as well as the presenters of these TMLR papers. We are thus running another year of the TMLR-to-ICLR pilot program at the upcoming ICLR (2025).
In 2024, we only considered TMLR papers with outstanding or featured certifications. This year, we will be expanding the pool of TMLR papers invited for a poster presentation at ICLR. Over the past few months we have been asking the action editor (AE) of each submission whether they find it appropriate for presentation at ICLR. For ICLR 2025, we will use this AE recommendation together with other signals, such as reviews and reviewer scores, in addition to outstanding and feature certifications, in order to invite the authors of approximately 100 TMLR papers to present their work at ICLR in 2025. For this year’s pilot, we will consider TMLR papers that have been published for at most two years prior to ICLR 2025 and were not presented at any previous ICLR or similar conference venue.
We plan to send out invitations to the authors of the selected TMLR papers later this year, with more details.
With this continued pilot program, we hope to highlight quality work from TMLR to a broader research community and to understand better how journals and conferences can collaborate with each other to improve the publication paradigm in machine learning.
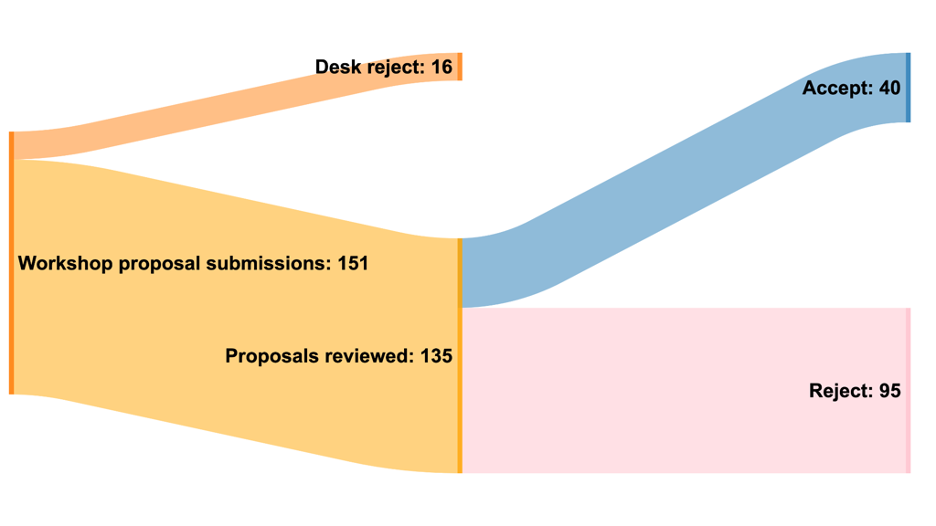


 Table 1:
Table 1: 





